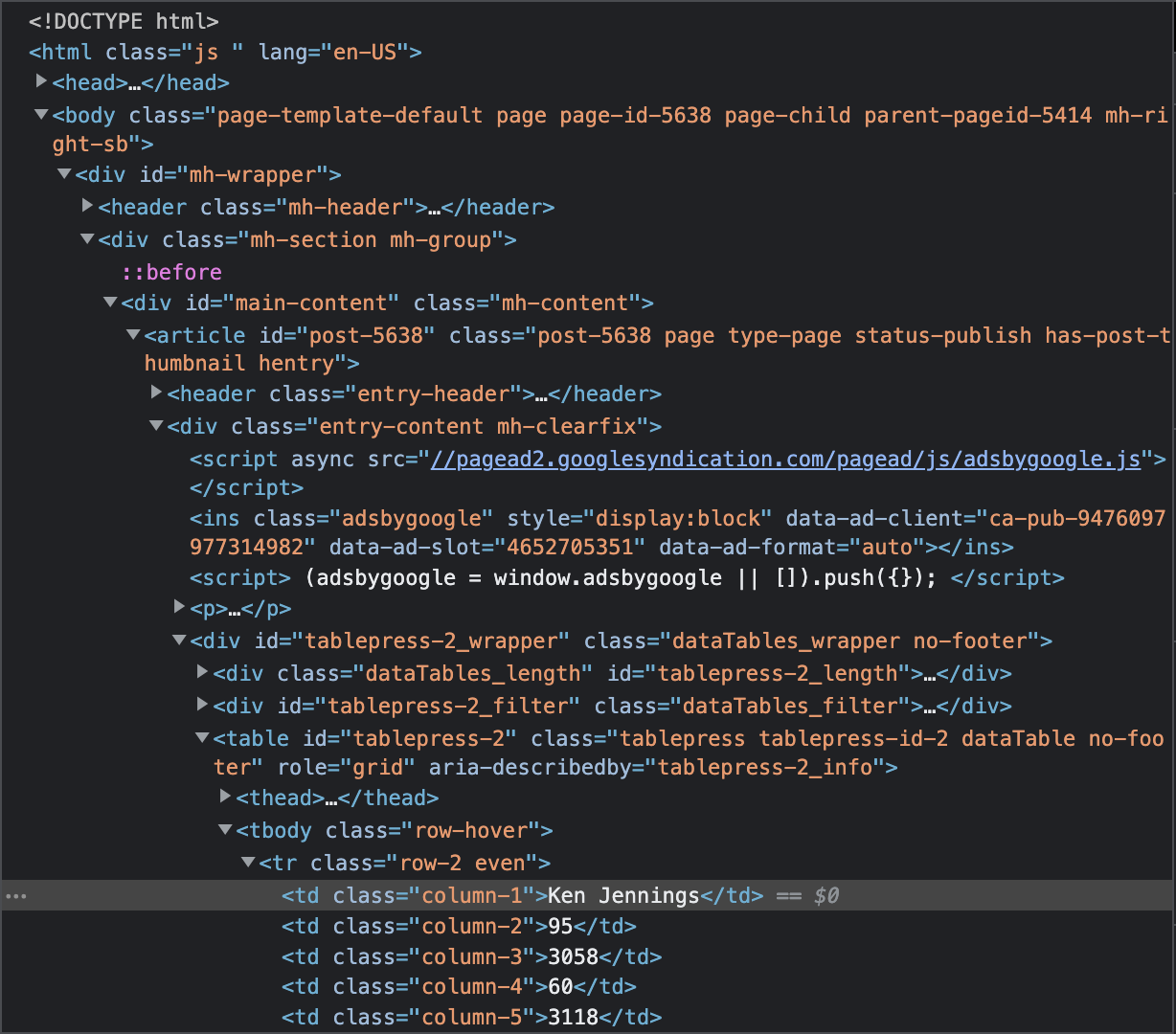
Example of HTML for a Jeopardy Website:
If we want to scrape/get information from the HTML of a webpage, we can do this using BeautifulSoup. BeautifulSoup is a Python library that is used to pull data out of HTML files. It makes it easy to parse through the HTML tree and pull information from specific tags.
1. Import BeautifulSoup:
2. Create a BeautifulSoup object and tell Python to parse HTML data, specifically the file passed in. In this case, let’s use “Jeopardy.html”, the HTML file of the jeopardy website in the example above. (Website: https://thejeopardyfan.com/statistics/the-300-club)
3. There are many methods we can now use to pull data from certain tags in the HTML file.
|
Method |
What the Method Does |
|
soup.head |
Returns the head tag as a tag object |
|
soup.body |
Returns a tag object representing the first body tag |
|
soup.find(“tag”)
soup.find(“tagName”, {“tag-attribute” : “attribute-value”}) |
Returns the first instance of the inputted tag as a tag object
Commonly used when trying to pull tags from the same class in this format: soup.find(“tagName”, {“class” : “value”}) |
|
soup.find_all(“tag”)
soup.findAll(“tagName”, {“tag-attribute” : “attribute-value”}) |
Returns a list of tag objects, where the tag objects are all instances of the tag that was inputted
Commonly used when trying to pull tags from the same class in this format: soup.findAll(“tagName”, {“class” : “value”}) |
|
tag.text |
Returns a string containing the text in a given tag |
For our example, let’s say we wanted to pull all the names of the jeopardy players on the website. We can use soup.findAll() to accomplish this. We have to figure out what to pass as the parameter in the findAll() method. We figure this out by looking at the HTML code:
As we can see, the tag for the jeopardy player name line is “td” and the class for this line is “column-1”. Using this information, our findAll() method would be the following:
Printing output this prints these tag objects:
As we can see, the resulting list contains the names of the Jeopardy players, but since findAll() populates the list with tag objects and not just the strings of the Jeopardy names themselves, we must clean this up ourselves.
Once these changes are made, the resulting list is the list of names from the HTML file: