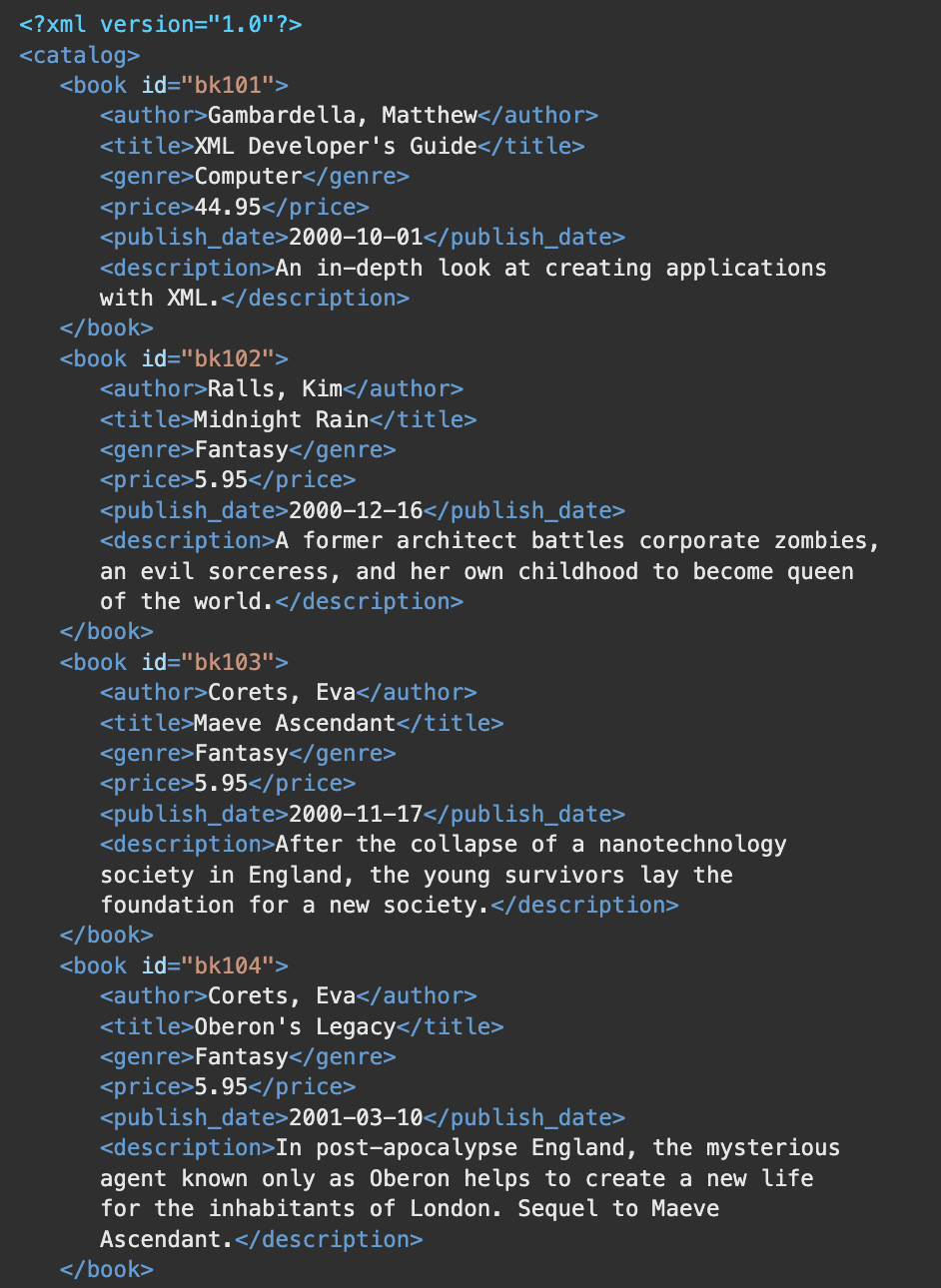
Example XML file:
In this case: <catalog> is called the root element, which is where the XML tree starts and from which child elements branch out from.
1. We use Python’s built-in module xml.etree.ElementTree to parse XML data. First, we need to import the module. It’s convention to import xml.etree.ElementTree as ET.
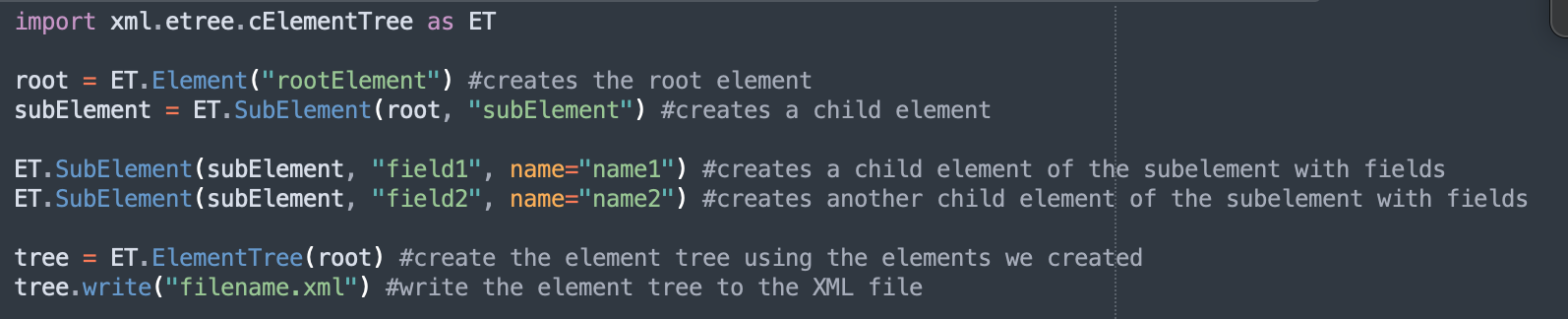
2. First, we have to create an ElementTree object like this:
If we print catalogTree, we get the ElementTree object:
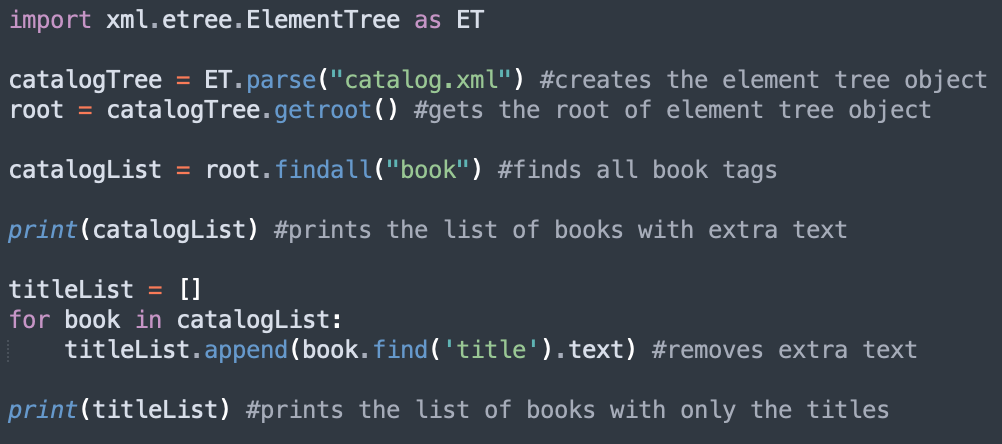
3. Then, we have to get the root element, which in our example above is catalog. We can do this with the following line:
If we print the root, we get this:
For example, if we wanted to find the first “book” tag in our XML example from above, we could use this line of code:
Printing catalogElement gives us this:
If we wanted to get a list of all the book tags, we could use this line:
Printing catalogList gives us a list of the “book” tags in the XML file:
5. Notice how each book element doesn’t just print by itself: it prints with a lot of other text. We can get rid of this “extra” text by iterating through each element in catalogList and using .text:
Notice that we use a child element of the book element (title, author, genre, etc. from our XML file) inside our find() method.
This outputs the titles of all the book tags (shown below).
6. We can also add each of these titles to a new list to create a list of all the book titles in our XML file:
This gives us a list with all the titles of books in the XML file.
We can similarly do this with any child element of the book tag, such as the genre, author, or price of the book.